同一品牌存在多种标签,该标签查询系统主要用于对各品牌商品进行标签标识,方便各商家进行搜索查找。该系统需要利用 JSON 文档存储的结构灵活特性对商家及品牌标签进行管理,为商家按标签等维度自由组合提供高并发查询。项目之前采用MongoDB做为其存储层, 后面采用国产数据库 SequoiaDB 替换 MongoDB,保证系统能够更高效和快速的运转。目前,该系统的商家、品牌及产品标签关联维度数据量达到10亿以上。
标签查询系统业务示意图
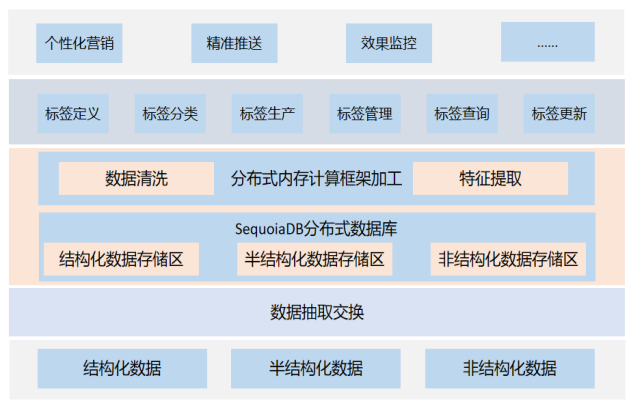
SequoiaDB 的 JSON灵活存储结构特性助力营销平台中的标签查询系统构建, 满足将结构化数据与源头数据的致存储, 同时也可以根据加工的需要,根据规则加工成JSON嵌套的半结构化数据。也能够将非结构化数据,如图片等进行存储,并且给这些图片,添加标签分类存储等。
1)结构化、半结构化和非结构化数据统一存储管理
SequoiaDB 的Multi-Mode存储特性提供了能够同时存储结构化、半结构化( JSON 文档类型存储 )和非结构化数据的机制。其中结构化和半结构化数据存储在记录存储引擎中, 而非结构化则存储在LOB大对象存储引擎中。这两套引擎可以在一个集群中同时工作, 相互之间不会产生影响。结构化数据的访问操作可以使用巨杉数据库的 JAVA API, 也可以使用标准的SQL 读取接口,如JDBC等。半结构化数据则只能使用巨杉的JAVA API 接口实现访问,也支持Spring-Data的方式进行访问。而非结构化数据除了标准JAVA API接口以外,还可以使用S3、Posix等访问接口进行访问使用。
2)高性能实时性能响应
通过分布式架构、多维数据分区、高性能索引和数据压缩等机制,无论是结构化、半结构化还是非结构化数据,在大数据量下依旧可以保持性能平滑扩展,系统可以实时响应。在性能测试中,对比巨杉数据库,传统NAS的非结构化存储方案想要达到同样的数据吞吐量,至少需要3倍以上的磁盘数量。
3)多活与灾备
巨杉数据库的原生分布式架构,提供了引擎级别的数据多副本和高可用,并使用Raft算法来保证数据一致性。同时,在跨数据中心层面,可以做到分布式集群为单位的容灾和多活,在满足数据安全要求的前提下,降低了部署和运维难度。
同时,巨杉也支持异地灾备机房的定期追加更新。用户可以通过定义异地灾备机房的同步策略,让灾备机房定期进行日志文件的同步,使得灾备机房与主机房的数据拥有一定的时间差异,避免手工误操作。






