
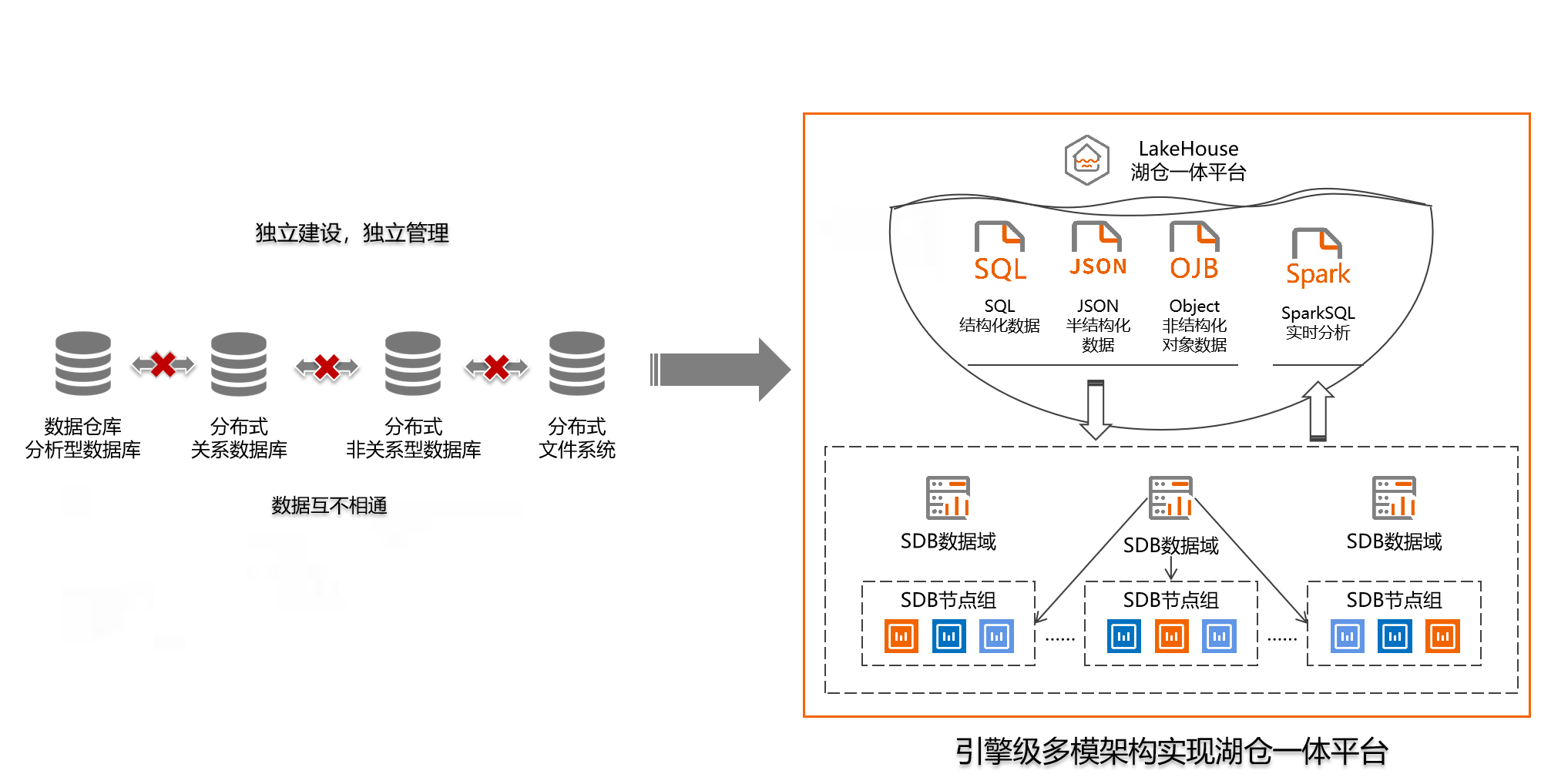
随着企业数字化转型、智能化升级的推进,企业数据量的增长以及非结构化数据的形成,对企业的数据应用及分析性能提出了新的要求。融合结构化、半结构化、非结构化数据的综合处理需求正在爆发。作为一种新型的开放式架构,湖仓一体打破了数据湖与数据仓库的割裂体系,并融合两种架构的优势,底层可支持多种数据类型并存,且为上层应用提供 “一数一源” 的数据基础设施,同时支持实时查询和分析。能够更为有效的帮助企业实现数据管理水平、降本增效、提升用户体验等数字化转型目标的提升。
以SequoiaDB分布式数据库作为底座打造的SequoiaDP湖仓融合平台,充分发挥湖仓一体架构优势,在具备多模能力,即兼容多种SQL结构化数据、JSON半结构化数据和Object非结构化对象数据引擎的基础之上,还可提供包括流式计算、高性能列存分析引擎、跨引擎数据ACID一致性等能力。广泛适用于在保持事务一致性的前提下,同时进行高性能实时分析的场景。
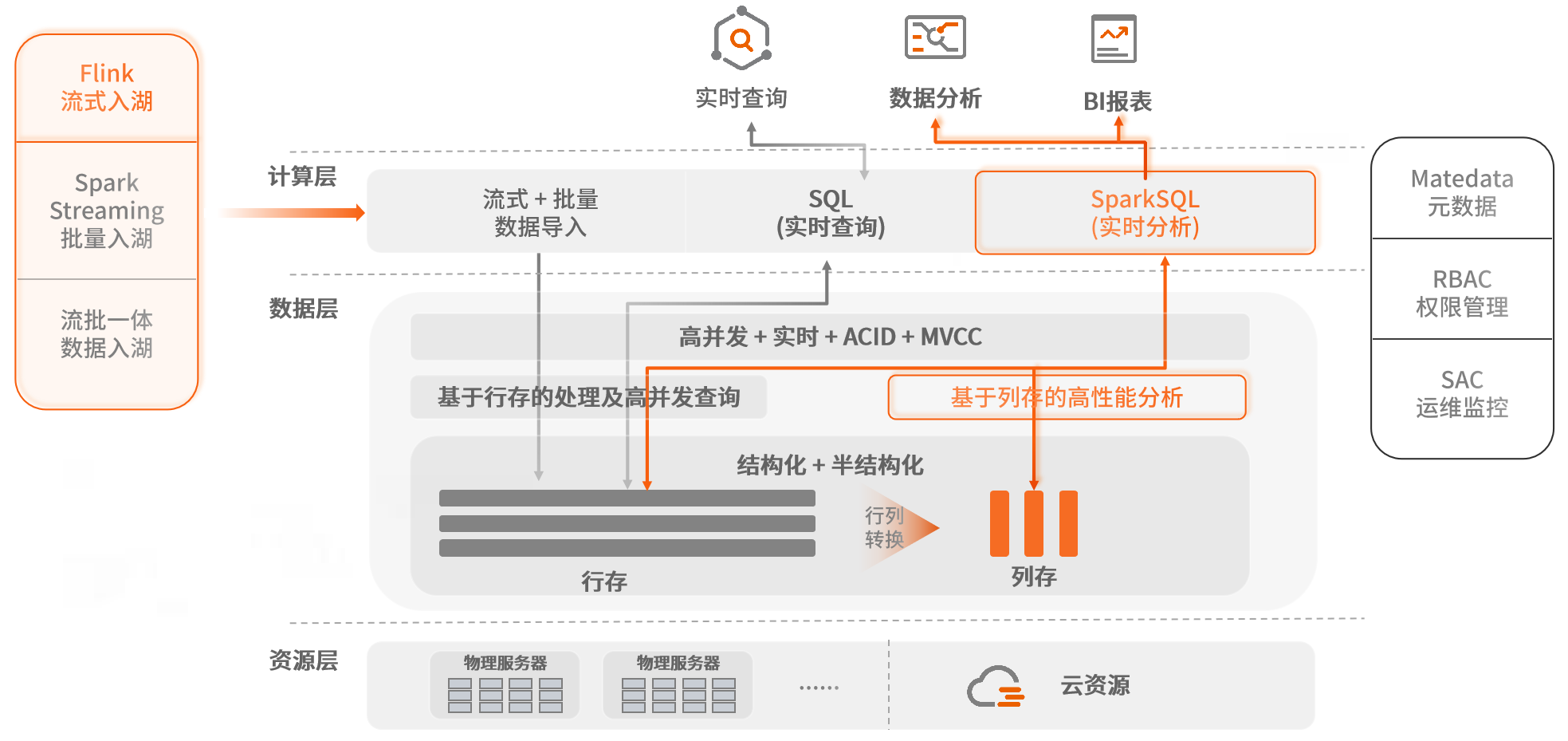
对接业界主流Flink架构,采用巨杉数据库的Flink connector实现更低延时的数据入库,业务数据通过 流式/批量 加载到巨杉数据库中,数据从业务发生到实时入湖的时延在秒级。
通过Sequoia-Spark计算实例,基于行存拥有了高效的分析能力,在引入列存架构后,在相同的表上可以实现更高的压缩率,最大可能地降低查询响应时间。
多副本技术,支持多种级别的容灾部署形态:同城双中心、同城三中心、两地三中心及三地五中心等,根据实际业务及监管要求,最大程度提升系统可用性和容灾能力,降低RTO/RPO。
在分析性能方面,我们引入了列存引擎,在海量数据的查询分析场景中,能够尽量减少无关IO、避免全盘扫描、实现更高的压缩率,大幅提升数据实时查询分析效率。
数据是银行的核心资产,随着企业数字化转型,为了配合数据资产的管理与应用,该银行需要调整组织架构和数据管理体系,实现更完善地管理数据、更高效地使用数据。
在过去多年的数字化建设进程中,该银行面临着业务数据分散地存储在各个生产系统的情况,特别是非结构化数据的处理非常分散,没有集中管理。随着业务转型,线下业务开始线上化、结构化,且受监管要求,银行迫切需要把各种影像等非结构化数据归档处理。而传统的数据生命周期管理模式又加剧了数据割裂的程度,企业缺乏以全量数据为基础的360度视图。
随着业务的发展,企业越来越需要对全量数据进行分析,迫切需要进行集中统一存储。此外,业务的爆发式增长,也对更高的实时响应速度等方面提出了挑战。
以巨杉数据库SequoiaDB为基础构建的湖仓融合平台,主要提供全量数据的实时服务,同时提供对海量数据进行采集、计算、存储、加工以及基于全量数据的数据价值发掘和数据科学工程等。能够有效解决随着业务复杂化及互联网、移动业务带来的海量数据增长在数据治理、挖掘方面的挑战。
湖仓融合平台一方面可以将大数据和数仓的加工结果,以及核心库来的实时数据流,对外以直接API或标准SQL的方式,提供高并发低延迟的数据访问服务。另一方面也可以将核心库里面的数据实时抽取过来进行数据粗加工,如用户统一资产视图、实时绩效等业务。
通过对海量历史与实时数据的采集、计算、存储和加工。全量数据平台为应用上层多变的业务逻辑与底层稳定的数据结构提供中间层统一的标准和口径,满足企业业务和数据的沉淀,实现生产系统瘦身、历史数据实时化,降低重复建设,增强企业差异化竞争优势。






