银行对公知识图谱在项目之初因为需要使用JSON文档的灵活存储格式,因而采用了MongoDB作为其底层数据存储层。因为服务支持和需要使用Spark做数据加工等原因,行方采用同样支持JSON文档灵活存储的国产分布式数据库SequoiaDB替换MongoDB。在该系统中,巨杉数据库 SequoiaDB 将银行对公客户信息按照数据表血缘关系进行加工打平,最后提供给业务人员查询及访问。由于加工数据表数量庞大,该系统指定客户为主键信息,并将其打平成嵌套 JSON 字符串。通过查询打平后的 JSON 嵌套字符串,业务人员能够高效完成对对公知识图谱的查询。目前,该系统数据量达到10亿以上, 查询响应实现毫秒级别。
多种模型数据的存储:银行在构建知识图谱的时候,除了会有对公客户信息这类结构化数据难以外,还会有打平加工出来的嵌套JSON文档的半结构化数据, 同时还会有少量的非结构化数据,如文件等。这些数据我们需要进行统一存储和管理
灵活丰富的JSON文档:因为知识图谱的数据涉及到加工打平的操作,所以会有把多条记录加工成一条记录的行为。在这种场景下就要求有灵活丰富的JSON文档能够进行各类嵌套以及字段的追加。
Spring-Data持久化框架的支持:为了简化开发架构,提升开始效率,需要对Spring-Data持久化框架的支持。
海量数据实时在线:近10亿的数据实时在线,提供毫秒级别的实时查询服务。
数据量快速增长:因企业的信息在实时变化,应用程序也需要对变化的数据进行采集。
数据加工分析:支持通过采用Spark RDD将大批量的结构化数据进行加工分析处理,最终形成一条大的JSON文档记录;
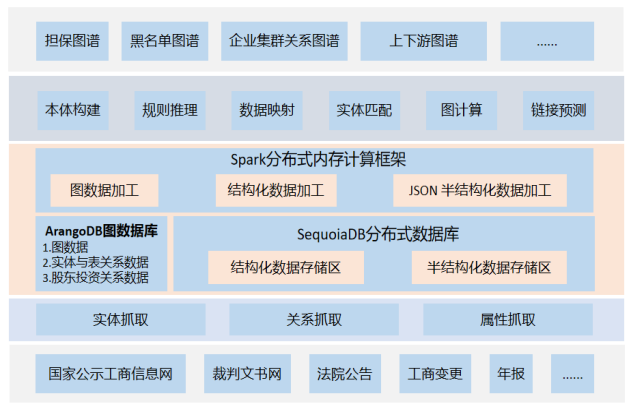
某大型银行的对公知识图谱






