
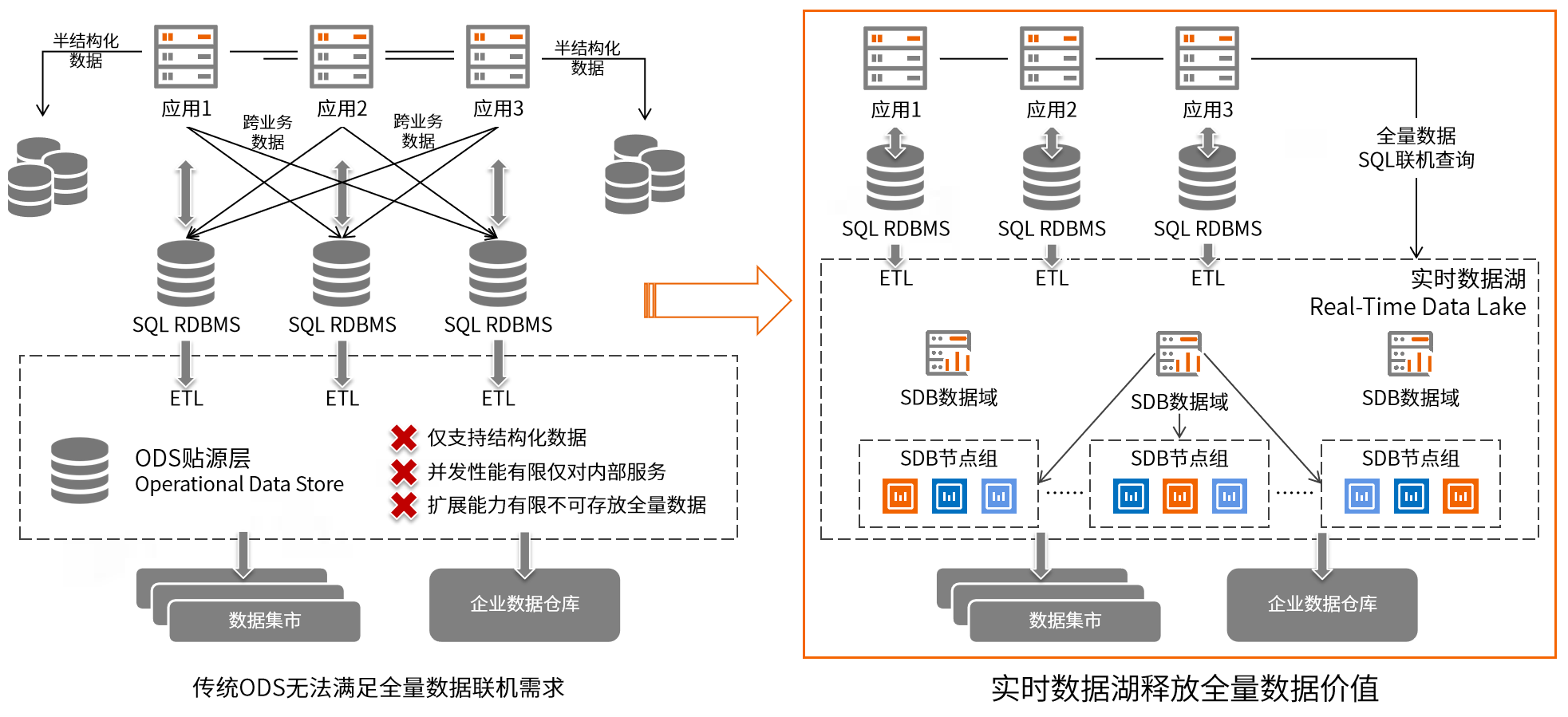
随着移动互联网的快速发展,各行业应用场景不断丰富,海量数据爆发增长的同时,数据类型也变得更加多样化。凭借多模、可弹性扩缩容等技术特性,数据湖(Data Lake)成为了企业数字化基础设施建设的新选择。但是数据湖并不具备高并发实时处理能力,如何向全量数据提供高并发实时在线处理,成为了企业关注焦点,对此,实时数据湖(Real-Time Data Lake)这一理念应运而生。相较于数据湖 “Schema-on-read” 的方式不同,实时数据湖基于文档型数据库SchemaLess的特性,屏蔽数据源端表结构变化对DataLake存储层的影响,无需关注Schema结构,数据无缝实时持续写入。特别是可提供在结构化及半结构化数据上建立索引的能力,以支持面向终端业务海量的实时并发性能要求。与传统ODS相比,实时数据湖具备更强的弹性扩展能力及并发能力,更加适合企业在数字化的新业态下,直接提供对客的全量数据访问服务。
基于SequoiaDB分布式文档型数据库构建的实时数据湖,基于分布式能力、流式计算等能力,可作为可无限扩展的ODS数据贴源层,提供跨团队、跨业务的数据实时自由访问。在兼顾数据灵活性的同时,也拥有更强的并发能力和横向水平扩展能力。可同时提供 > 10000并发连接下的万亿级数据实时SQL查询性能,帮助企业构建历史数据平台、全量数据平台、实时数据中台等,实现海量数据可实时对客服务的多种场景。
支持跨结构化、半结构化的多模数据处理,助力企业级客户降低迁移风险,降低研发人员学习成本,提升迁移效率。
分布式架构下支持全量数据流式入湖,数据从业务发生到提供访问的时延在秒级,为各类业务提供7*24小时实时数据融合处理能力。
支持百PB级存储容量,支持在线水平弹性扩缩容,轻松应对数据爆发式增长,可灵活应对不同规模、不同类型的数据应用场景。
随着互联网的发展,网上银行、手机银行等新业务形态兴起,银行对于数据管理和应用的需求趋于多样化、复杂化。银行为了构建起全行数据资产 “建、看、评、用” 的管理体系,需要不断丰富和完善数据中台的服务能力,探索数据应用价值,通过数据产品和数据服务赋能金融业务。
目前该银行基于Hadoop构建了行内大数据平台,主要用于承载行内海量数据分析和部分业务系统联机查询等功能。但是随着新银行核心系统和新信用卡核心系统的陆续投产,核心系统的数据量急剧增长,大数据平台也无法完全承接核心系统的查询服务能力。
为此该银行迫切需要构建统一的高性能数据平台,以应对新业务的需求,同时解决全行数据对外联机查询所存在的痛点:
历史数据平台将为行内各个业务系统提供海量数据存储与高并发数据访问服务。源端各个业务系统能够通过申请和配置,将其历史数据迁移至数据平台,然后再由数据平台为各个业务系统提供高效的数据访问服务。
在数据同步方面,通过数据交换平台将数据仓库或者外围系统的数据同步至历史数据平台,将建设一个统一的、灵活的支持T+1的数据同步方式。各个业务系统将根据自身对于数据同步的需求,灵活配置不同的同步方式。






