
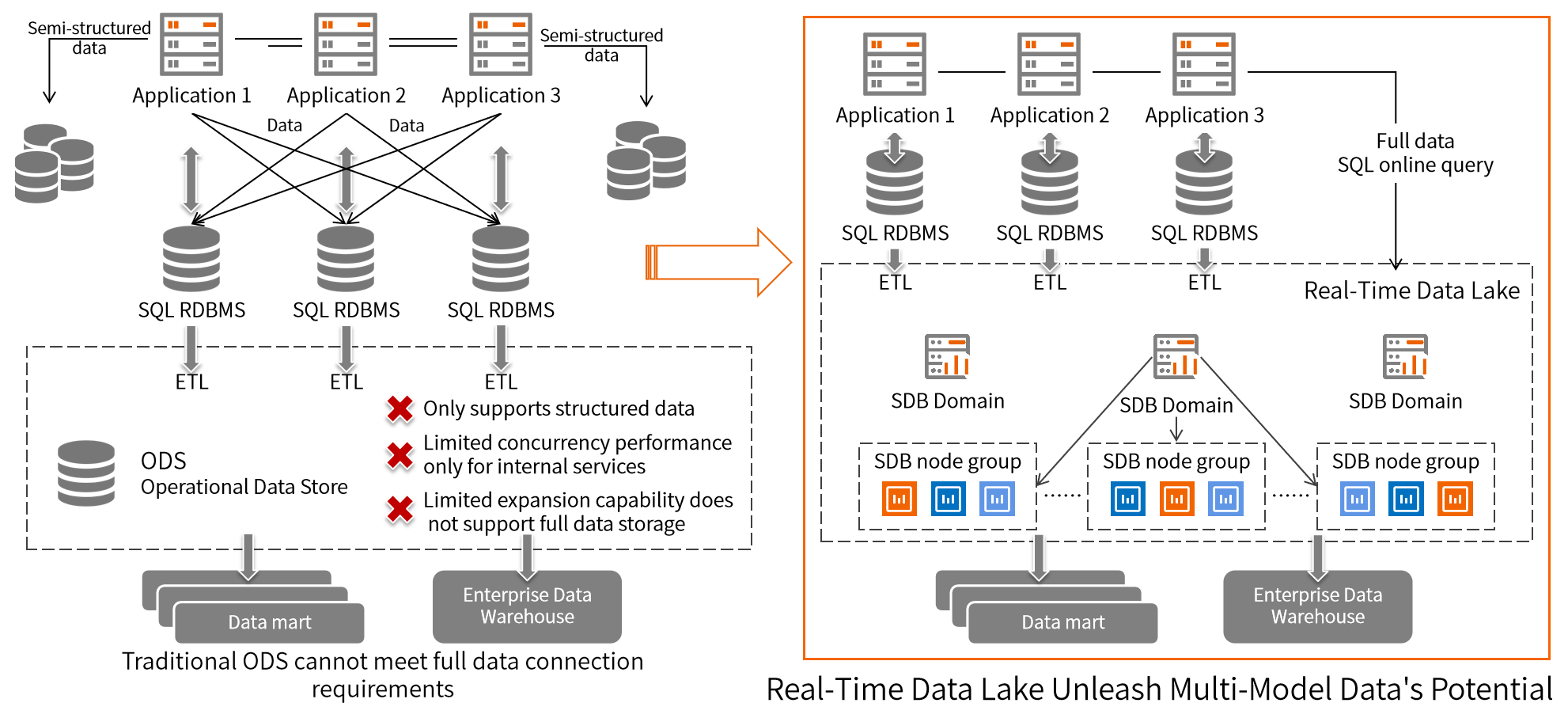
With the rapid development of the mobile Internet, the application scenarios of various industries are constantly enriched, and the massive data growth has exploded while the data types have also become more diversified. With multi-mode, elastic expansion and contraction and other technical characteristics, the data lake (Data Lake) has become a new choice for enterprise digital infrastructure construction. But the data lake does not have high concurrency real-time processing capabilities, how to the full amount of data to provide high concurrency real-time online processing, has become the focus of corporate concerns, in this regard, the real-time data lake (Real-Time Data Lake) the concept came into being. Compared to the data lake "Schema-on-read" approach is different, Real-Time Data Lake based on the characteristics of the document-based database SchemaLess, shielding the data source table structure changes on the DataLake storage layer, no need to pay attention to the structure of the Schema, the data seamless real-time continuous writing. In particular, it can provide the ability to build indexes on structured and semi-structured data to support the real-time concurrent performance requirements of massive end-oriented business. Compared with traditional ODS, real-time data lake has stronger elastic scalability and concurrency, which is more suitable for enterprises to directly provide full-volume data access services to customers in the new business of digitalization.
Real-time data lake built on SequoiaDB Distributed Document-Oriented Database, based on distributed capabilities, streaming computing and other capabilities, can be used as an infinitely scalable ODS data posting source layer to provide cross-team, cross-business data access in real time. While taking data flexibility into account, it also has stronger concurrency and horizontal scalability. It can simultaneously provide real-time SQL query performance for trillions of data under 10,000 concurrent connections, helping enterprises to build historical data platforms, full-volume data platforms, real-time data platforms, etc., and realizing various scenarios in which massive data can be served to customers in real time.
Support cross-structured and semi-structured multi-modal data processing to help enterprises reduce migration risks, reduce the learning cost of R&D personnel, and improve migration efficiency.
The distributed architecture supports full data streaming into the data lake with the latency time between the application and the access restricted to within seconds and conducts 24-7 integrated Real-time data processing for various businesses.
Provide hundreds of petabytes of storage capacity, and support online horizontal elastic scaling to easily manage the explosive growth of data and data application scenes of different scales and types.
With the development of the Internet and the rise of new business forms such as online banking and mobile banking, the demands for data management and applications in the banking industry tend to be more diversified and more complicated. To build a comprehensive management system for the overall data assets, banks need to continuously enrich and improve the services of the data middle platform to explore the application value of data and empower financial services through data products and services.
At present, the bank has an internal big data platform based on Hadoop, which is mainly used to carry out functions such as internal massive data analysis and online queries for some business systems. However, with the launching of the new banking core system and the new credit card core system, the big data platform cannot fully undertake the query services of the core system as the data size of the core system is expanding dramatically.
Therefore, the bank urgently needs a unified high-performance data platform to meet the new business requirements, and at the same time the pain points in an external online query of the bank's full data need to be solved:
The historical data platform will provide massive data storage and high concurrent data access for various business systems within the bank. Each business system at the source side can migrate its historical data to the platform through application and configuration. Then the platform can provide efficient data access for each business system.
Data synchronization is conducted through a data exchange platform to migrate data from the data warehouse or a peripheral system to the historical data platform. Data synchronization will be conducted in a unified and flexible manner to support T+1 synchronization. Each business system can adopt different synchronization methods based on its own needs for data synchronization.





