
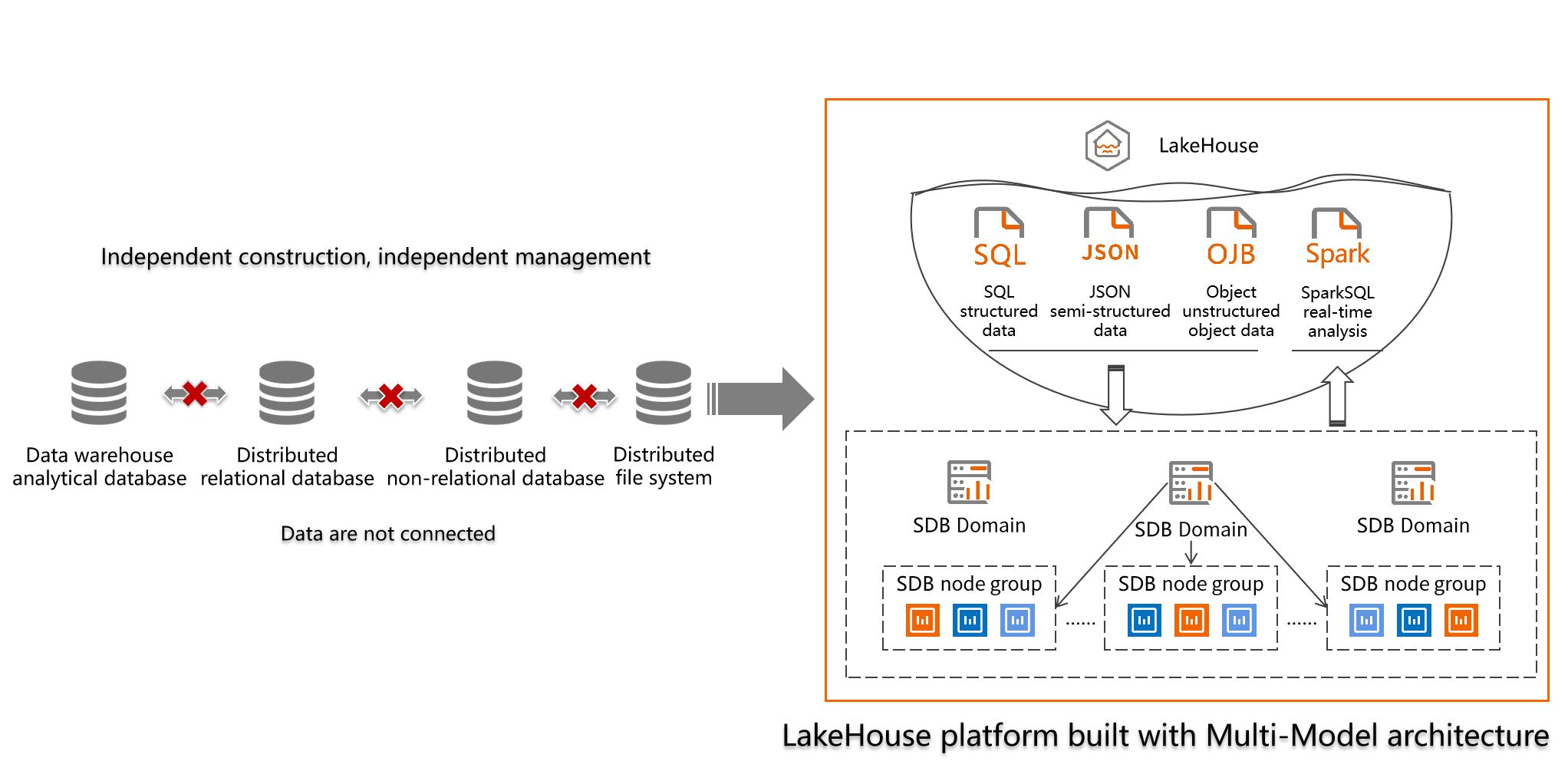
The digital transformation and intelligent upgrading of enterprises lead to the growth of enterprise data and the emergence of unstructured data. Therefore, new requirements are being placed on enterprise data application and analysis performance. The demand for comprehensive and integrated processing of structured, semi-structured, and unstructured data is surging. As a new open architecture, the Lakehouse bridges the gulf between the data lake and data warehouse while integrating the advantages of the two architectures. Multiple types of data are supported at the bottom layer and single source data infrastructure is provided to the upper applications while supporting Real-time query and analysis at the same time. The Lakehouse can help enterprises achieve digital transformation goals, including high-level data management, cost reduction, efficiency improvement, and user experience enhancement.
SequoiaDP is built on the distributed database of SequoiaDB to fully tap into the advantages of the Lakehouse architecture. SequoiaDP is a Multi-model platform that supports various engines of SQL structured data, JSON semi-structured data and Object unstructured object data. On top of this, it also features stream computing, high-performance column storage analytical engine, and consistent cross-engine ACID. It can be widely used in high-performance real-time analysis while maintaining transaction consistency at the same time.
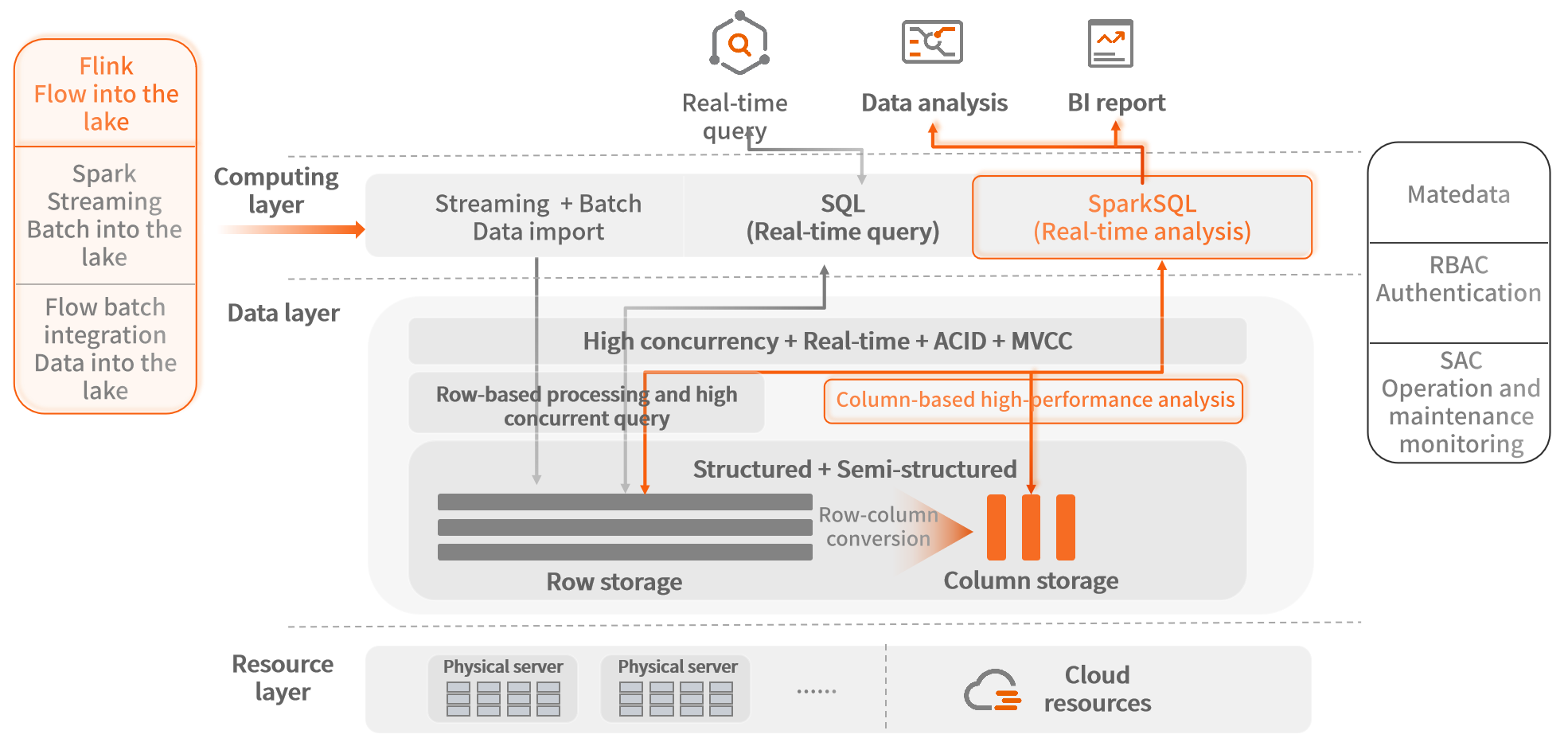
Following the mainstream architecture of Flink, SequoiaDP adopts SequoiaDB’s Flink connector for lower latency in data ingestion. The business data is ingested into SequoiaDB through streaming and batch loading. The latency between data generation and data ingestion is restricted to seconds.
Based on the computing instances of Sequoia-Spark, SequoiaDP is capable of efficient analysis with row storage. With the introduction of the column storage architecture, a higher compression rate is achieved with the same table, and the query response time is reduced to the greatest extent possible.
SequoiaDP adopts multi-copy technology and supports various levels of disaster recovery deployment: double centers in the same city, triple centers in the same city, triple centers in two locations, and quinary centers in three locations, etc. In compliance with the business reality and regulatory requirements, SequoiaDP maximized the availability and disaster recovery capabilities with low RTO and RPO.
For analysis performance, we use a columnar storage engine, which can minimize irrelevant IO, avoid full-disk scanning, achieve higher compression ratios, and thereby greatly improve the efficiency of real-time query and analysis for massive data.
Data is the core asset of a bank. With the digital transformation of enterprises and for the management and application of data assets, the bank needs to adjust its organizational structure and data management system to better manage and use data.
In the process of digital construction in the past few years, the bank has been troubled by the dispersed storage of business data in various production systems, especially those unstructured data. With business transformation, offline services are being moved to online to become structured. Also as required by the regulators, the bank urgently needs to archive and process unstructured data such as images. The traditional data lifecycle management model has exacerbated data fragmentation. This model fails to offer a 360° view of full data.
With the development of business, the need for full data analysis is growing increasingly. Centralized and unified storage is urgently needed. In addition, the explosive growth of the business has also raised challenges in many aspects, such as faster Real-time response.
The Lakehouse is built on the database of SequoiaDB to provide Real-time services for full data. Meanwhile, it can undertake the collection, calculation, storage, and processing of massive data and engage in data value discovery and data science engineering based on full data. It can effectively solve the challenges in data governance and mining, which come with the growing business complexity and the massive data upsurge brought by the Internet and mobile services.
The Lakehouse, on one hand, can provide high-concurrency and low-latency data access to the processing results of big data and data warehouses, as well as Real-time data streams from the core library through direct API or standard SQL. On the other, the data in the core library can also be extracted in real-time for rough data processing, such as unified asset view and Real-time performance.
With the collection, calculation, storage and processing of massive historical and Real-time data, the full data platform can provide a standardized middle layer between the upper layer featuring variable logic and the bottom layer of stable data structure. This can meet the enterprises’ need to cope with service and data accumulation and realize the downsizing of the production system, real-time access to historical data, the reduction of repetition, and the enhancement of the competitive differentiation of enterprises.





