With the expansion of banking business and the increasing demand for bank sites, major commercial banks are building intelligent sites driven by a new wave of technologies. The self-service counters in commercial banks are one of the first intelligent service.
Large commercial banks, such as Guangfa Bank and CMBC, have been introducing self-service counters in recent years nation-wide. In the future, with one-stop integrated clerk and artificial intelligence, major commercial banks will fully utilize the intelligent transformation of these self-service kiosks.
In average, large commercial banks have more than 300 to 400 business systems. Each business system has a complete technology stack, and there are many inter-dependencies and relationships with different businesses. The business and technical complexity are by far more complex than other industries. The banks have hard requirements for platform reliability and stability to guarantee zero data loss and zero error rate. These requirements have great demands on back-end database.
The self-service counter, as a new generation of application for commercial banks, poses new challenges for data management. SequoiaDB uses its support for unstructured storage, structured query transactions, horizontal scalability, high availability, and multi-site disaster recovery to provide data stability and security. SequoiaDB fully supports self-service banking services in Guangfa Bank, and Minsheng Bank. This has brought huge improvements to the business.
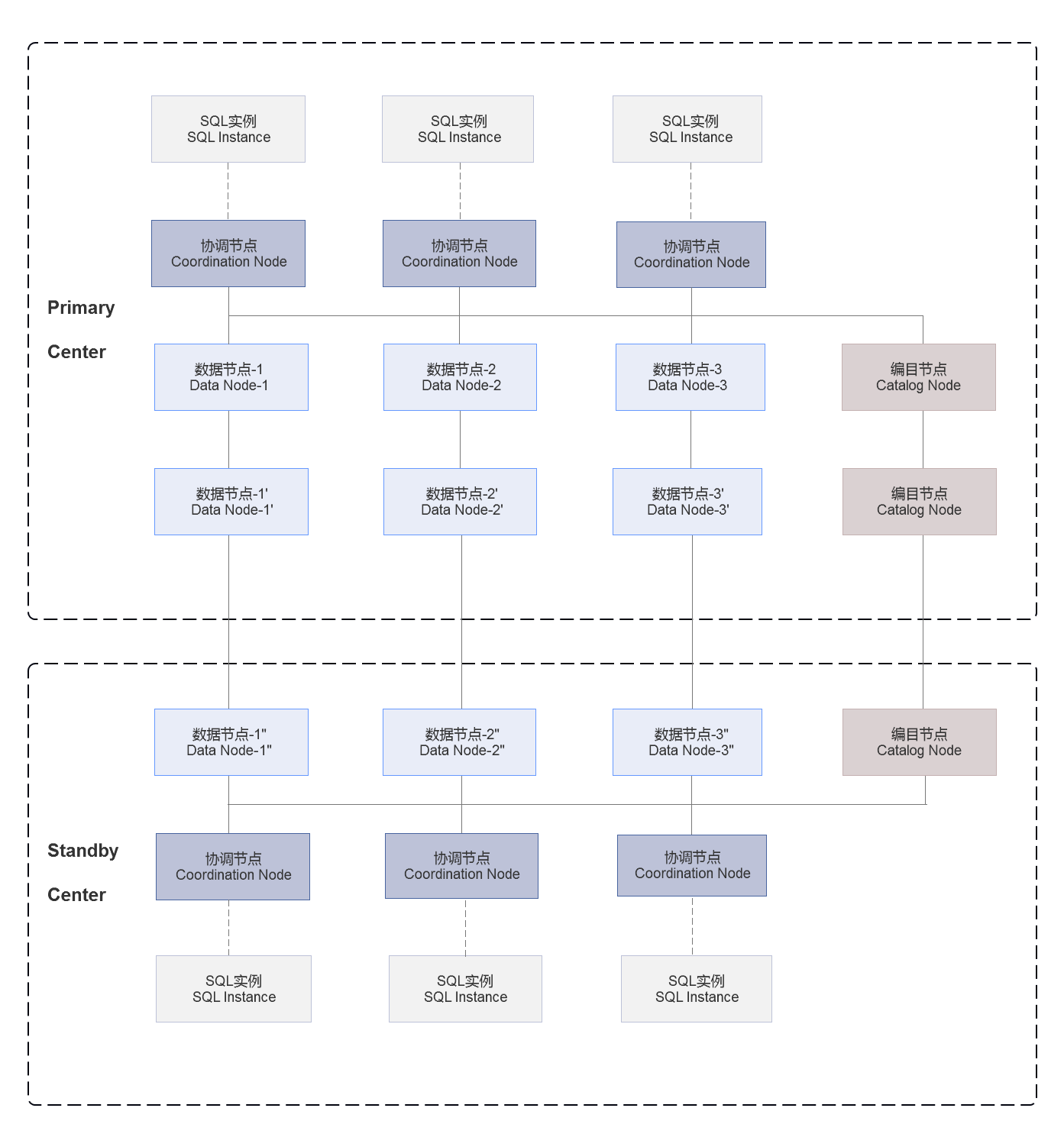
SequoiaDB 2DC Active-Active Deployment
SequoiaDB is a distributed and unstructured data management platform with the underlying data engine. It has been applied to more than 50 large-scale banking services including Minsheng Bank and Guangfa Bank. In a large-scale commercial banks, the total number of nodes deployed in SequoiaDB cluster reached 122 physical servers, and 1530 logical nodes. The number of platform service banking kiosks exceeded 840. The end to end response time was within milliseconds, with data disaster recovery and dual-active configuration.
Unstructured data storage
As a distributed transnational database, SequoiaDB provides a mechanism for simultaneous storage of structured and unstructured data. The unstructured data is primarily stored in the form of Large Object(LOB). SequoiaDB 3.0 provides a standard POSIX file system interface based on the object storage API so that objects can be natively accessed by any operating system that supports POSIX protocol standard. This allows users to migrate from NAS to SequoiaDB without any modifications to the application.
In SequoiaDB, the large object storage engine can slice unstructured files of various sizes into small storage blocks. In the cluster, storage blocks are saved in multiple data groups according to the hash mapping to achieve efficient concurrent access, and provide object ID for file access.
In SequoiaDB, the LOB storage structure is divided into metadata file (lobm) and data file (lobd). The metadata file stores the metadata model of the entire LOB data file, including a series of data structures such as the idle status of each page, the hash bucket, and the data mapping table. The data file stores user's real data. All data pages after the data header are divided according to the page size, data pages do not contain any metadata information.
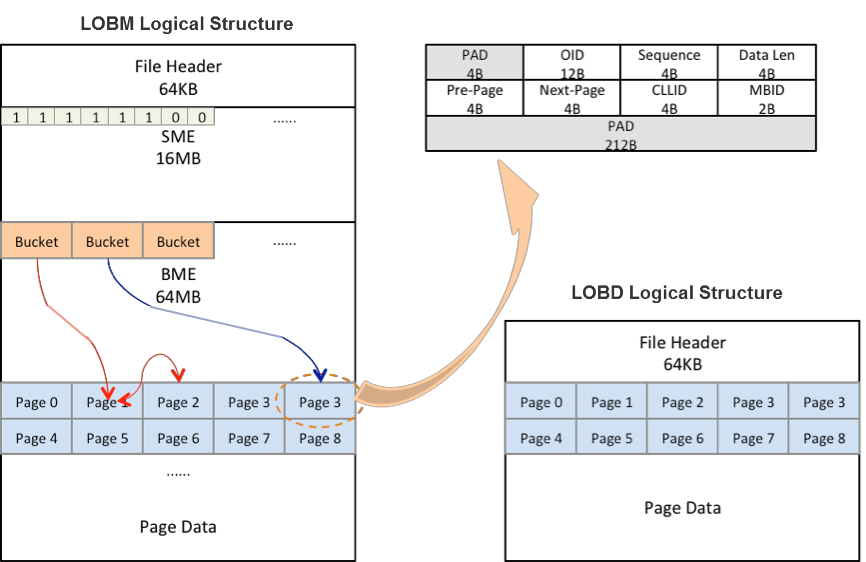
Unlike the record engine of structured data, the unstructured storage of SequoiaDB provides a native object file block storage mechanism, which is suitable for image-type large files and ticket-type small files. In the process of storing and retrieving small files in SequoiaDB, each data block uses a hash algorithm to determine its physical location, so no physical lookup operation is performed. The database does not need to maintain the physical location table of each object file. Thus, the security, throughput, and response time are much better than other similar object storage.
Disaster recovery
The native distributed architecture of SequoiaDB provides multiple data replica at storage engine level. It guarantees data high availability and data consistency through Raft algorithm and distributed disaster recovery mechanisms. It reduces data security deployment, operation and maintenance difficulties while meeting data security requirements.
SequoiaDB adheres to the design principle of computing storage separation. Its SQL parser and actuators often run in different processes than data storage and transaction control. Using the characteristics of the database's own distributed and three-copy replication, the data is scattered and placed in multiple data centers. Each data center is configured with a local SQL service node. From the perspective of the application, there is no need to pay attention to the underlying layer. The master-slave architecture of the database only needs to connect to the local SQL service node through JDBC for read and write operations. In this architecture, each SQL node is completely peer-to-peer and can handle both read and write operations. All transaction control, consistency control, lock wait and other mechanisms are provided directly by the underlying distributed database.
For example, with this architecture, the city A data center 1 serves as the main site and provides synchronous data replication with data center 2 in the same city. For the data center in city B, if the bandwidth is sufficient, you can choose to use the synchronous replication mechanism to transfer data from the data center in city A.[M1] When the bandwidth is insufficient, you can choose asynchronous replication mode.
SequoiaDB also supports incremental batch update mechanism for remote disaster recovery DC. You can synchronize the log files in a way to ensure that there is a certain delay between in the disaster recovery DC and the main site which could help certain mis-operation scenarios.
High performance and real-time performance response
With distributed architecture, multi-dimensional data partitioning, high-performance indexing, and data compression, the image platform maintains smooth performance and real-time response regardless of unstructured data or structured data under large data volume. In the performance test comparison, the traditional NAS solution needs at least 3 times more disks than SequoiaDB to achieve the same throughput.
The following is the test data for the unstructured data management in the actual test environment of SequoiaDB:
• 2GB/s overall throughput, distributed architecture
• 6-node x86 server, 36 clusters of SAS disks in the entire cluster
• Traditional solution, high-end configuration: 1.5GB/s 120 disks or more
100% Write Scenario

100% Read Scenario

Mixed Business Scenario

About SequoiaDB
SequoiaDB is the leading distributed database company in China. Since the establishment in 2011, SequoiaDB has been dedicated to the research and development of the new generation distributed database management system. In 2017 and 2018, SequoiaDB has been listed in Gartner’s database report, and is the first Chinese DBMS vendor listed.
The main products of SequoiaDB includes distributed relational database and SequoiaCM enterprise content management software. The application scenarios includes distributed online transactions, data lake, distributed content management and etc.
SequoiaDB now has more than 1000 enterprise customers and community users. SequoiaDB has been deployed on core systems of more than 50 major financial institutions, like banking, insurance and security clients of Fortune-500 Level.






