Data Lake solution
Provide one-stop service for online data
SequoiaDB provides a unified management platform for enterprise history and real-time data to activate the core value of enterprise data. Through the collection, calculation, storage and processing of massive history and real-time data, the data lake provides a unified layer of standards and caliber for the application of the upper-level business logic and the underlying stable data structure to meet the requirement of business and data precipitation, realizing slimming of production systems, reducing redundant construction and the cost of chimney collaboration, also enhancing the competitive advantage of enterprises.
In recent years, with the continuous development of IT technology and big data, more and more enterprises have retained data as their valuable assets for a long time. At the same time, the continuous development of micro-services and distributed technologies makes online applications no longer built in a "chimney" way, but requires flexible data access by a large number of atomic service components in a single data pool. This makes the historical data package of some traditional online applications more and more heavy, and the flexibility is greatly reduced, resulting in the final database being overwhelmed and the overall performance of the application is low. On the other hand, as the demand for big data continues to increase, the data that has been archived needs to be re-wired to meet the requirements of online, real-time use, query and analysis, which requires the online large-scale offline data to be “online” and "servitization". These demands make the data lake become the direction of IT construction and investment in major enterprises.
|
Lack of agility In the face of fast iterative business needs, applications place higher demands on agile development. Traditional IT architecture and waterfall application development processes often fail to meet the demands of different business units and high-speed transformations. |
System independent data isolation Under the traditional chimney SOA application development architecture, different services can only be interconnected through the ESB enterprise data bus. When application requirements are constantly changing, multiple service modules may face interface adjustments and even refactoring, resulting in inefficient application iteration. |
Low data accessibility A large number of application systems are unable to provide direct online service capabilities for full historical data in the face of high concurrency, high reliability, and low latency requirements from mobile terminals and the Internet, resulting in only partial information being visible to users and reduce users’ experience. |
|
High pressure on the core system With the rise of the mobile Internet, more and more systems are facing high concurrency, low latency and high throughput pressure, resulting in frequent expansion of a large number of business systems, and the maintenance teams are exhausted. |
Difficulties in transformation of cloudization and micro-service The traditional databases rely on the minicomputer architecture, and the introduction of micro-services has caused the data storage to be unable to expand |
High IT costs In facing of massive data, enterprises need to manage real-time data and historical data with expensive hardware costs and software licenses, which causes IT capabilities becoming a huge bottleneck restricting enterprise development. |
The data lake is not a special technology or product, but a set of data services that provide data integration and provide online services in the enterprise. Different from big data, which is mainly for internal analysis and statistical mining, the data lake is mainly facing to external end customers, providing high concurrency and low latency online business support. The data lake system can be divided into four parts, including the ODS area, the operational data storage area, data processing scheduling area, and the external service area.
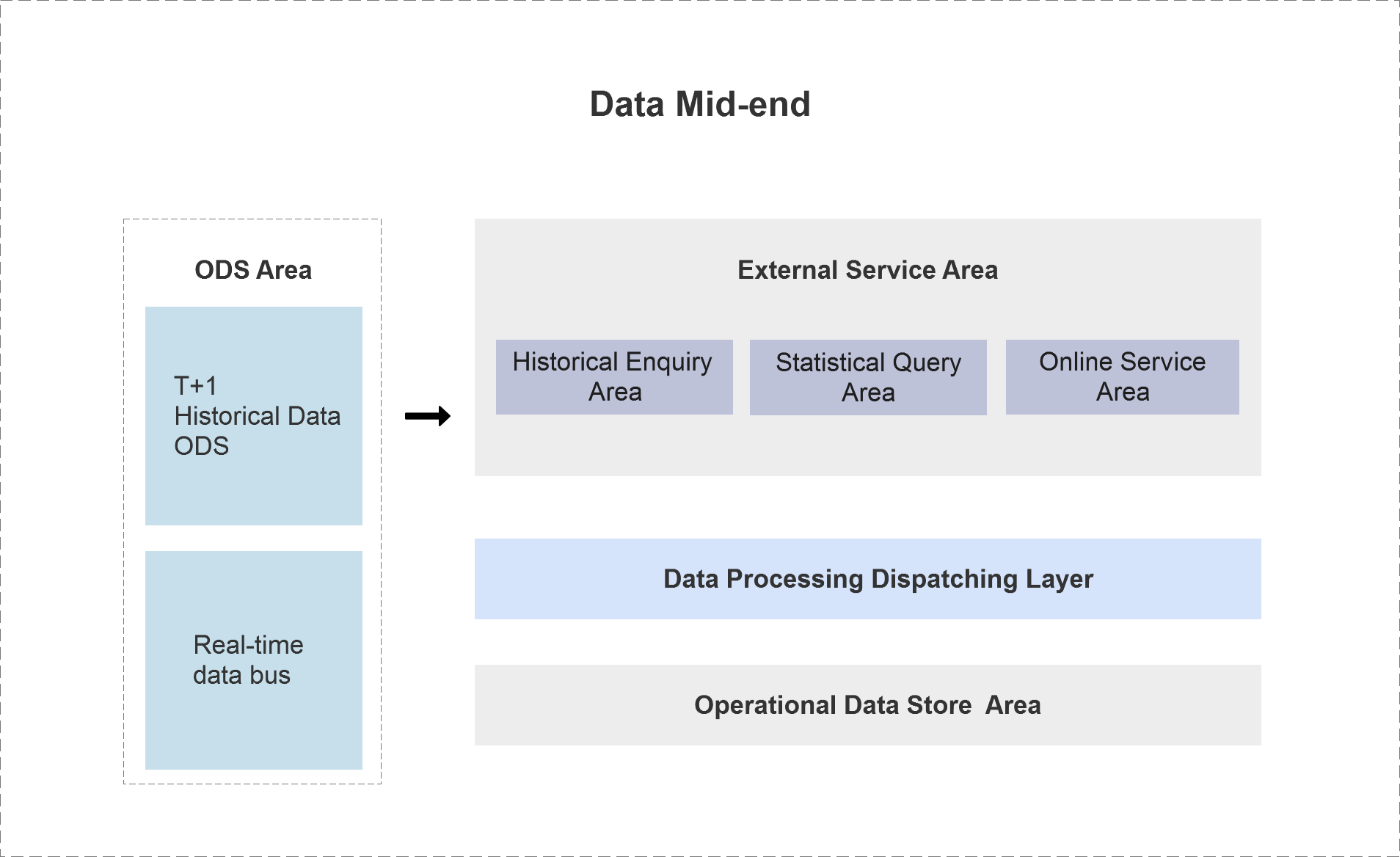
The ODS layer is the synchronization layer of data access. It originates from various business systems and provides initial data access(data preparation area) for subsequent data cleaning and processing, which is related to offline data and (quasi) real-time data.
The operational data storage area stores user's detail data and the original raw data. In general, the data structure in the source data storage area is consistent with the content and the original business system, and users can also apply this area for online archiving of data.
The data processing dispatching area cleans and processes the patch source data to form a data structure that can be directly applied to the external online application. As the application continues to incrementally iterate, the data processing scheduling area acts as a bridge between the original detail data and the external application data, shielding the difference between the external application and the internal data structure of the enterprise, and weakening the barriers of data exchange between applications.
The external service area is the business data that the application actually accesses. The external service area can be divided into a historical detail query area, a free query area, and an online service area, depending on the different types of application.
The historical detail query area can be used as a view mapping interface to directly connect an external application to historical detail data that creates a suitable index, so that the external application can directly access the massive historical detail data. At the same time, for some detailed data that needs simple processing, it can also be stored separately after combing through the data processing scheduling area.
The free enquiry area mainly faces to non-fixed inquiry services such as post-audit supervision and self-service statements. In general, data provided to free-query services often does not undergo complex data processing, allowing applications to directly access portions of raw data.
The online service area provides T+0 (quasi) real-time data access capability, and the data source often directly connects to the (quasi) real-time data synchronization service of the ODS layer, so that the application could access to the latest data in online business system in real-time through the data lake.
|
Infinite Elastic Scalability Infinitely flexible and scalable distributed architecture, which could easily carry PB-level external online service data |
High Concurrency and Low Latency Serve hundreds of thousands of concurrent online services and provide millisecond real-time data access performance at the same time |
Multi-index Create multiple user indexes in different fields and dimensions of the user table to support complex and flexible millisecond-level online query requirements |
|
Multi-model Support SQL execution engines for online transactions, mixed services and statistical analysis. Support standard structured data and files, unstructured data storage and online access of object types. |
Multi-tenant Provide characteristics of multiple instances and data area isolation. The computing and storage resources from different types of business systems do not interfere with each other. |
High availability Maximize data reliability and availability, and support rich disaster recovery strategies such as 2-DC in the same city, 3-DC in two cities, and 5-DC in three cities. |
|
Agile development |
|
|
Total amount of Online Data |
|
|
Reduce Risks |
|
|
Reduce Cost |
|





